最近、チーム内で「ある特徴を持った文章かどうか判定したい」という業務課題が生じました。今回のブログではその課題に対して「基準データとの類似度を測る」仕組みを使ってアプローチしてみようと思います。
なお、前述の「ある特徴」が具体的に何を指すかは機密情報にあたるため、ブログでは「ニュース記事の文章を入力し、カテゴリを判定する」という題材に置き換えて話を進めていくことにします。判定ロジックの実装次第では「入力されたニュース記事が、特定のカテゴリに該当するか否か」の判定(いわゆる 2 クラス分類)もできる可能性があると考えています(最後の方で触れます)。
言語は python、要素技術としては「文章のベクトル変換(embedding)」「ベクトルデータベース」あたりです。ご興味のある方はぜひご一読ください!
目次
記事の概要
目的
学習済みのモデルを用いて、ニュース記事の文章からカテゴリを判定する一連の流れを紹介します。
想定読者
この記事は文章のベクトル変換(embedding)に興味がある方やRDBMS でのベクトル検索に興味がある方を対象に書いています。
実験内容とアプローチ
実験内容
はじめに、今回の実験内容を具体化します。データセットとしては自然言語処理分野のド定番「Livedoor ニュースコーパス」を使います。
過去の「Livedoor ニュース」の記事がセットになったデータセットです。カテゴリは「Sports Watch」「家電チャンネル」「MOVIE ENTER」など9種類で、合計7,300を超える記事が用意されています。収集時期は2012年9月上旬とのことで、記事の日付は2011~2012年のものが多いです。
株式会社ロンウイットがクリエイティブ・コモンズライセンスで公開してくださっています。詳細は下記リンク先をご覧ください。
Livedoorニュースコーパス (株式会社ロンウイットさま)
各カテゴリのデータの 7 割を「基準データ」とし、残り 3 割を「評価用データ」とします。基準データを使って「カテゴリを判定する仕組み(以下、カテゴリ判定システム)」を構築し、評価用データを使って精度(正答率)を測定するような流れになります。

アプローチ
実験内容が決まったところで、次にアプローチの仕方を考えます。
同じカテゴリのニュース記事は、文章の意味が比較的近いはずです。つまり文章同士の類似度を比較できれば、次のようなアプローチで判定できそうです。
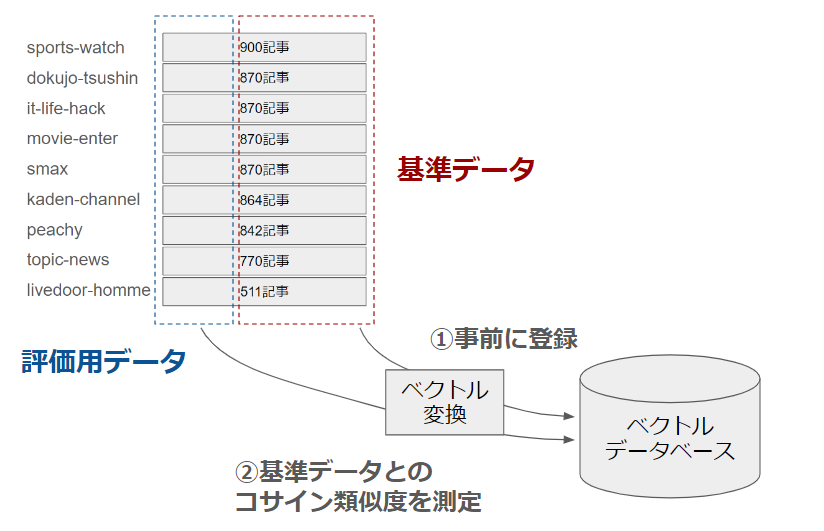
1) 各カテゴリの基準データをあらかじめどこかに登録しておく。
2) 評価用データが どのカテゴリの基準データに類似しているかを調べる。
3) 類似している基準データが多いカテゴリを判定結果とする。
さて、1)に「基準データを登録しておく」と書きましたが、文章のまま登録したとして果たして類似度が測れるでしょうか?残念ながら答えは No です。コンピュータは字面では意味の近さが分かりません。意味の近さを測るには、文章をベクトルというものに変換する必要があります。
ここでベクトルとその関連用語を説明します。
数値ではないデータを数値化することをベクトル変換(ベクトル化)といいます。
画像や音声などをベクトル変換する技術も存在しますが、今回のブログでは文書(自然言語)のベクトル変換のみ扱います。自然言語のベクトル変換は、Embedding とも呼ばれます。
ベクトルの実体は 1 次元配列という認識でとりあえず OK です。数値化することによって、コンピュータがデータの近さを判断できるようになります。例えば下図のようなベクトル表現を得られれば、犬・猫、クルマ・バイクがそれぞれ似ているといった判断ができるようになります。

どのようなベクトル表現を獲得できるか(ひいては、類似度判定の精度)は、ベクトル変換の仕組みによってまったく違います。 古くからある仕組みとしては 文書内の単語の出現回数をカウントする BoW などがありますが、近年は深層学習のモデルを使うことが多くなっているように感じています。特に Transformer 系のモデルが性能が高いと評判です。
このブログでは sentence-transformers というモデルを使いますが、他にも様々なモデルが公開されているようです。ご興味のある方は「transformer」や「BERT」というワードで検索してみてください。
余談ですが、最近話題の生成系 AI の ChatGPT や GPT-4 の「T」は transformer の略です。その transformer を、テキストの生成ではなく理解に特化させたのが BERT です。GPT の威力を知っていると、BERT も何となく凄い感じがしてきますよね。
ベクトルはしばしば「向きを持った量」と説明されることがありますが、コサイン類似度は 2 本のベクトルがどれくらい同じ向きを向いているのかを表す指標です。自然言語処理で文の類似度を評価するときには、このコサイン類似度を使うのが定石です。
コサイン類似度は-1~1の範囲に正規化され、その値によって解釈が異なります。1に近いほど意味が似ている文章ということになります。(1が完全一致)
ベクトルデータベースとは、名前の通りベクトルの検索に特化したデータベースです。
簡単なデモのようにデータ数が少なければ、メモリ上でベクトルの類似度を計算すれば事足ります。しかし「メモリ使用量が大きくなる」「アプリケーション終了時に消える」「アプリケーションとデータが密結合でありスケーラビリティが低い」などの特徴があるため、多くのベクトルデータを扱うには不向きです。また、リレーショナルデータベースに格納すればデータの永続化はできますが、ベクトル間の類似度を評価してくれる機能は基本的にはありません。そこで、ベクトルデータベースが必要になるわけです。
ベクトルは高次元になるにつれて、計算量が指数的に増加したり類似度が評価しにくくなるという問題があります。いわゆる「次元の呪い」というやつです。ベクトルデータベースでは、近似最近傍探索(ANN)という手法を用いて、この次元の呪いを解決しています。
ANN は「近似」と名がつく通り、すべてのデータ点間の距離を総当たりで計算するのではなく、近いと推定される点の距離計算だけを行う方法です。そのため、必ずしも最も近いベクトルを検索できるわけではありませんが、この精度の低下は許容範囲であることが多いためベクトルデータベースではよく使われています。
近似最近傍探索については以下の資料で詳細に解説されています。
近似最近傍探索の最前線 (東京大学生産技術研究所 助教 松井勇佑さま)
ざっくりまとめると
- 字面では文章の類似度が分からないから数値化するよ。その数値をベクトルと言うよ。
- ベクトルの近さを測るにはコサイン類似度という指標を使うよ。計算方法は覚えなくて良いよ。
- ベクトル変換の結果を永続化するためにベクトルデータベースに登録するよ。
という感じです。これらの用語をつかって、前述のアプローチ案を書き直します。
1) 各カテゴリの基準データをベクトル変換し、ベクトルデータベースに登録しておく。
2) 評価用データを ベクトルデータベースに入力し、類似している(コサイン類似度が高い)基準データを調べる。
3) 類似している基準データが多いカテゴリを判定結果とする。
簡単なデモ
ベクトル変換、コサイン類似度の比較の流れを簡単なサンプルで示します。Google Colaboratoryで実行できるソースコードになっていますが、流し読みしていただいて大丈夫です。
1. ベクトルとコサイン類似度
基準データと評価用データの類似度を測ってみます。モデルを読み込んで各データをベクトル変換するプログラムは次のように実装できます。
# ライブラリのインストール
!pip install sentence-transformers
# モデルの読み込み
from sentence_transformers import util, SentenceTransformer
model = SentenceTransformer('stsb-xlm-r-multilingual')
# 基準データをベクトル表現に変換
demo1_reference_sentences = [
'会議に出る',
'打ち合わせに出席する',
'ミーティングに参加しない',
'ミーティングが長引く',
'その猫はミーティングという名前です']
demo1_reference_embeddings = model.encode(demo1_reference_sentences)
# 評価用データをベクトル表現に変換
demo1_test_sentence = 'ミーティングに参加する'
demo1_test_embedding = model.encode(demo1_test_sentence)
変数 demo1_reference_embeddings と demo1_test_embedding には、文章から変換されたベクトルが入っています。変数の形状と中身の一部を確認してみましょう。
print(demo1_reference_embeddings.shape) print(demo1_test_embedding.shape) print(demo1_test_embedding)
出力結果(配列表示の途中で省略):

この結果から、sentence-transformersで変換されたベクトルは768次元(=ベクトル1つあたりが要素数768の1次元配列)であることが分かります。
次にコサイン類似度を算出します。util.pytorch_cos_sim関数を使うだけで、基準データと評価用データのコサイン類似度を計算できます。計算後、各基準データとのコサイン類似度を表示してみます。
# 基準データと評価用データのベクトルの類似度を計算
demo1_scores = util.pytorch_cos_sim(demo1_test_embedding, demo1_reference_embeddings).numpy()
demo1_predicted_idx = demo1_scores.argmax(1).item() # スコアが最大のインデックスの取得
print('評価用データ:', demo1_test_sentence)
print('類似度が最も高い基準データ:', demo1_reference_sentences[demo1_predicted_idx])
print('類似度:')
for i in range(len(demo1_reference_sentences)):
print(f' {demo1_scores[0][i]} : {demo1_reference_sentences[i]}')
出力結果:

上記の出力結果を確認すると、評価データ「ミーティングに参加する」と字面が全然違っても意味が近い「会議に出る、打ち合わせに出席する」のコサイン類似度が高く、字面が近くても意味が正反対の「ミーティングに参加しない」のコサイン類似度が低くなっています。つまり sentence-transformers は、少なくともこのような短い文章であれば 意味が近い文章を 近いベクトル表現に変換できていることが分かりました。
2. ベクトルの可視化
続いて、類似した文章のベクトル同士が 近くに位置しているか可視化してみます。傾向を掴むにはデータが100個以上はほしいので、Livedoorニュースコーパス のデータを使用します。
基準データとしてカテゴリ「sports-watch」「it-life-hack」「movie-enter」からそれぞれ40記事ずつ使い、評価用データとして「movie-enter」の1記事を使います。次のような実装をすれば、ベクトル変換まで実行できます。
# ライブラリのインストール
!pip install sentence-transformers pandas umap-learn plotly
# コーパスデータのダウンロードと展開
!if [ ! -e ldcc-20140209.tar.gz ] ;then \
wget https://www.rondhuit.com/download/ldcc-20140209.tar.gz; \
fi
!if [ ! -d text ] ;then \
tar -zxvf ldcc-20140209.tar.gz; \
fi
from pathlib import Path
demo2_sports_articles = list(Path('./text').rglob('sports-watch*.txt'))
demo2_it_life_hack_articles = list(Path('./text').rglob('it-life-hack*.txt'))
demo2_movie_articles = list(Path('./text').rglob('movie-enter*.txt'))
def demo2_get_article_text(path):
with open(path, 'r') as f:
lines = f.readlines()
lines = list(map(lambda x: x.rstrip(), lines))
return ' '.join(lines[2:])
demo2_sentences = []
demo2_categories = []
# 基準データ
for article_path in demo2_sports_articles[:40]:
demo2_sentences.append(demo2_get_article_text(article_path))
demo2_categories.append('reference-data_sports-watch')
for article_path in demo2_it_life_hack_articles[:40]:
demo2_sentences.append(demo2_get_article_text(article_path))
demo2_categories.append('reference-data_it-life-hack')
for article_path in demo2_movie_articles[:40]:
demo2_sentences.append(demo2_get_article_text(article_path))
demo2_categories.append('reference-data_movie-enter')
# 評価用データ(基準データとして使ってない記事)
demo2_sentences.append(demo2_get_article_text(
demo2_movie_articles[-1])
)
demo2_categories.append('test-data_movie-enter')
# ベクトル変換
demo2_embeddings = model.encode(demo2_sentences)
次にベクトルを可視化します。さすがに768次元を可視化はできない(人間が理解できない)ため、UMAPという次元削減アルゴリズムを用いて2次元まで削減します。次元を削減すれば情報量は落ちますが、可視化が目的なので問題ありません。
import umap import plotly.express as px # 次元削減 demo2_embed = umap.UMAP(metric="cosine").fit_transform(demo2_embeddings) # 可視化 demo2_fig = px.scatter(x=demo2_embed[:, 0], y=demo2_embed[:, 1], color=demo2_categories, symbol=demo2_categories) demo2_fig.show()
出力結果:

この可視化結果に 今回とるアプローチを当てはめると「評価用データ(紫の矩形)の近くにはmovie-enterの基準データが多く存在している→判定結果としてmovie-enterと回答する」という流れとなり、正解できています。
今回使用したデータでは 同じカテゴリの基準データのベクトルが概ね近くに配置されたため正解できましたが、外れ値(黄色の破線で囲った箇所)も見受けられるので、評価用データ全てを100%正しく判定するのは難しそうな印象ではあります。まぁ、AIで精度100%が出ないのは当然の話なので、とりあえずカテゴリ判定をやってみましょう。
【本題】ニュース記事のカテゴリ判定(ハンズオン)
環境構築
筆者とPC環境が異なっても再現性を保つため、Dockerコンテナで開発・実行する手順を解説します。Docker Desktopをインストールするなど、Dockerを実行できるようにしておいてください。
実行PCのスペック(RAMの容量)によっては、sentence-transformers のインストール・インポート・モデル読み込み時にエラーが発生する可能性があります。そのときはベクトル変換のみGoogle Colaboratoryで実行する方法でお試しください。(手順は後述します)
docker-compose.ymlとDockerfileを作成する
任意のフォルダに、以下の構成でdocker-compose.ymlとDockerfileを作成します。
├── docker-compose.yml
└── python310 # フォルダ
└── Dockerfile
docker-compose.yml には以下のコードを記述します。ポート番号は適宜書き換えてください。
version: "3.9"
services:
database:
image: ankane/pgvector:v0.5.1
ports:
- 5432:5432
environment:
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=postgres
- POSTGRES_DB=postgres
volumes:
- vector_db:/var/lib/postgresql/data/
python-lab:
build:
context: ./python310
dockerfile: Dockerfile
restart: always
entrypoint: >
jupyter-lab
--allow-root
--ip=0.0.0.0
--port=7777
--no-browser
--NotebookApp.token=''
--notebook-dir=/workspace
expose:
- "7777"
ports:
- "127.0.0.1:7777:7777"
volumes:
- ./python310/root_jupyter:/root/.jupyter
- ./python310/workspace:/workspace
environment:
- POSTGRES_DB=postgres
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=postgres
- POSTGRES_HOST=database
- POSTGRES_PORT=5432
volumes:
vector_db:
python310/Dockerfileには次のコードを記述します。
FROM python:3.10.12
ARG DEBIAN_FRONTEND=noninteractive
RUN apt-get update && apt-get install -y \
tzdata \
&& ln -sf /usr/share/zoneinfo/Asia/Tokyo /etc/localtime \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
ENV TZ=Asia/Tokyo
RUN python3 -m pip install --upgrade pip \
&& pip install --no-cache-dir \
black \
jupyterlab \
jupyterlab_code_formatter \
jupyterlab-git \
lckr-jupyterlab-variableinspector \
jupyterlab_widgets \
ipywidgets \
import-ipynb \
jupyterlab-plotly
筆者の個人的な考えですが、機械学習を試す場合 pythonのバージョンは Google Colaboratory に合わせるのが無難だと思っているため、今回はブログ執筆時点の Google Colaboratoryと同じ3.10.12を使います。
ちなみにGoogle Colaboratoryに合わせるのが無難だと考える理由は、主に「メジャーな機械学習系ライブラリの多くは、Google Colaboratory環境のpythonのバージョンでは動作するようメンテナンスされていることが多い」「エラーが発生したときに役立つ情報が多い」の2点です。いずれもGoogle Colaboratoryのユーザー数が多いゆえのメリットだと思います。
ファイルを作成したら、下記コマンドでdocker-compose環境をビルドし開始します。
docker-compose up -d
ライブラリのインストール
python-labコンテナのターミナルで下記コマンドを実行します。
# ライブラリインストール pip install numpy pgvector "psycopg[binary,pool]" pandas sentence-transformers
sentence-transformersのインストールに失敗した場合は、ベクトル変換までをGoogle Colaboratoryの環境で行います。(インストールに成功した場合も、ベクトル変換はGoogle Colaboratoryを使った方が速いです)
Google Colaboratoryを開き、新しいノートブックを作成します。(Googleアカウントでのログインが必要です)

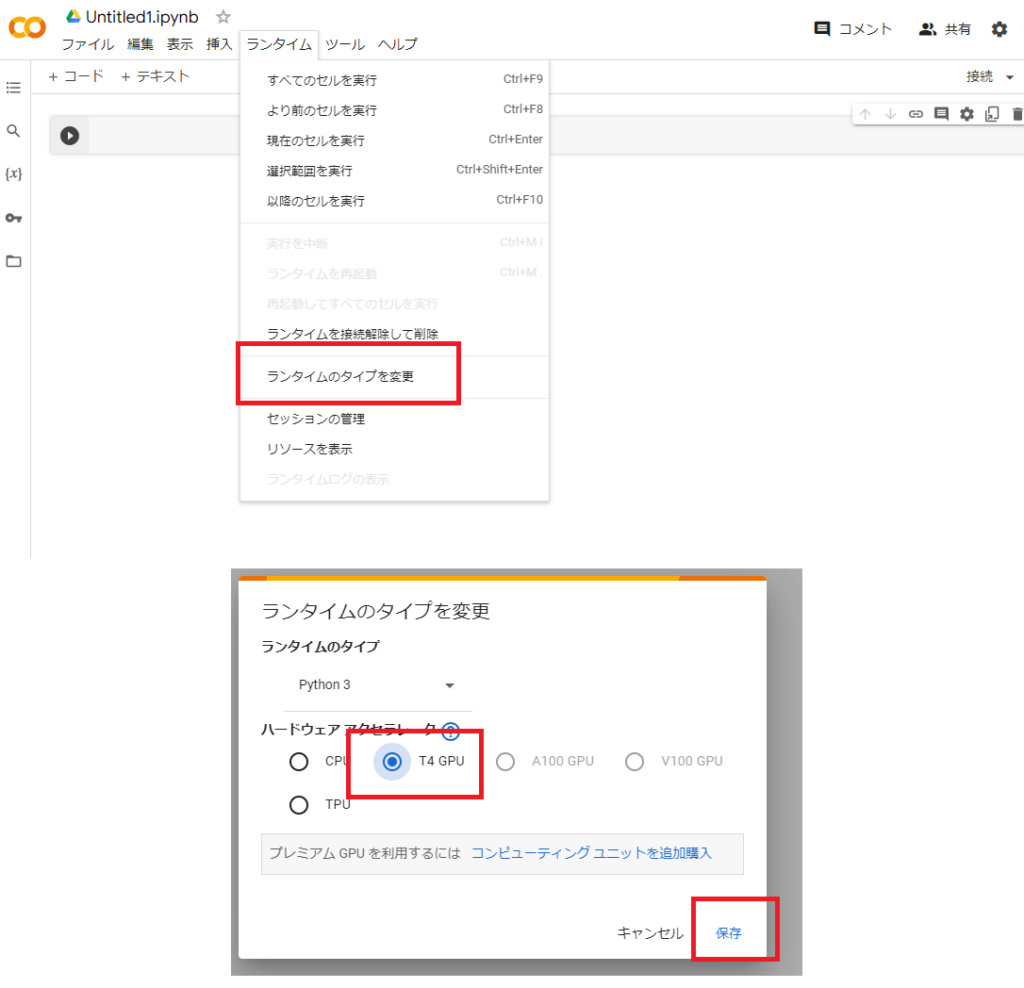
メニューバーの「ランタイム」-「ランタイムのタイプを変更」を選択し、表示されたモーダルの「ハードウェアアクセラレータ」でGPUを選択し「保存」ボタンをクリックします。
ノートブックのセルに下記のコードを貼り付けて実行します。実行完了まで3分程度かかります。
!pip install sentence-transformers
!wget https://www.rondhuit.com/download/ldcc-20140209.tar.gz
!tar -zxvf ldcc-20140209.tar.gz;
CORPUS_DIR = './text'
REFERENCE_JSON = './reference.json'
TEST_JSON = './test.json'
REFERENCE_EMBEDDED_NPY = './reference-embeddings.npy'
TEST_EMBEDDED_NPY = './test-embeddings.npy'
from sentence_transformers import util, SentenceTransformer
import numpy as np
from pathlib import Path
import os
import json
import pandas as pd
# モデルの読み込み
model = SentenceTransformer('stsb-xlm-r-multilingual')
# フォルダ名=カテゴリ名
categories = [
f for f in os.listdir(CORPUS_DIR) if os.path.isdir(os.path.join(CORPUS_DIR, f))
]
categories
# 基準データ
reference_sentences = []
reference_categories = []
# 評価用データ
test_sentences = []
test_categories = []
def get_article_text(path):
with open(path, 'r') as f:
lines = f.readlines()
lines = list(map(lambda x: x.rstrip(), lines))
return ' '.join(lines[2:])
def append_json(output_json_path, article_paths, category):
with open(output_json_path, 'a') as fp:
for article_path in article_paths:
json.dump({
"category": category,
"text": get_article_text(article_path)
}, fp)
fp.write('\n')
for category in categories:
# 各カテゴリの記事ファイルのパスを取得
articles = np.array(list(Path(CORPUS_DIR).rglob(f'{category}/{category}-*.txt')))
# 基準データと評価用データを 7:3 に分割
reference, test = np.split(articles, [int(articles.size * 0.7)])
# JSONファイルとして保存
append_json(REFERENCE_JSON, reference, category)
append_json(TEST_JSON, test, category)
reference_df = pd.read_json(REFERENCE_JSON, lines=True)
test_df = pd.read_json(TEST_JSON, lines=True)
reference_embeddings = model.encode(reference_df.text.values.tolist())
np.save(REFERENCE_EMBEDDED_NPY, reference_embeddings, allow_pickle=False)
test_embeddings = model.encode(test_df.text.values.tolist())
np.save(TEST_EMBEDDED_NPY, test_embeddings, allow_pickle=False)
このコードでは主に「①Livedoorニュースコーパスを扱いやすいように加工する処理」「②各記事の文章をベクトル変換する処理」を実行しており、npyファイルと jsonファイルが2つずつ生成されます。(2つずつ生成される理由は、基準データと評価用データを分割しているからです)
npyは②の結果(ベクトルの配列)をバイナリとして保存したファイルです。jsonは加工後のLivedoorニュースコーパスデータで、各ベクトルが属するカテゴリを取得するために使用します。どちらも後の手順で必要となりますのでダウンロードしておきましょう。
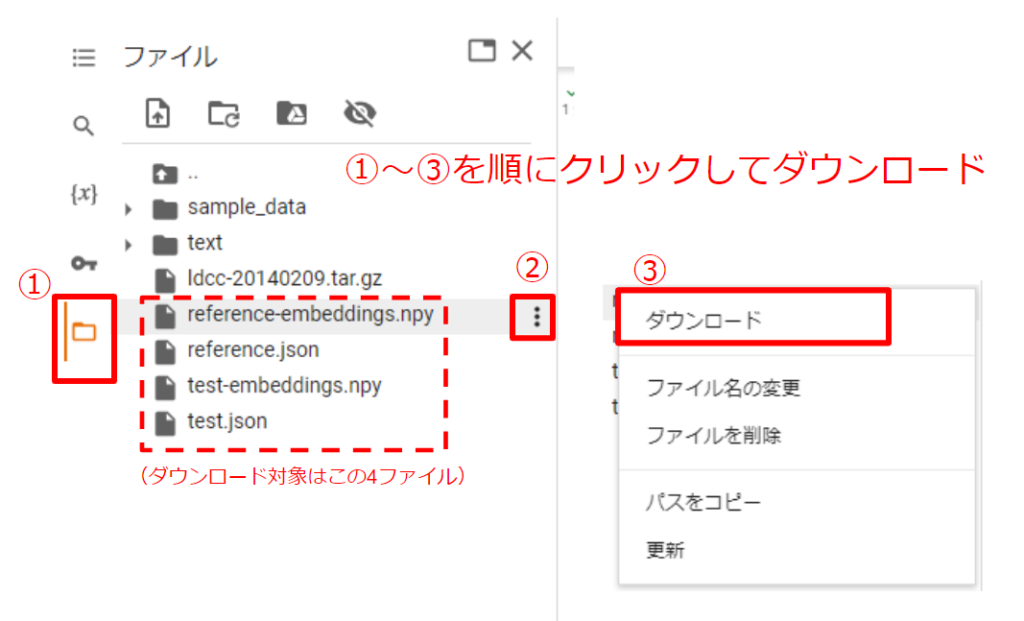
ダウンロードしたファイルは、python-labコンテナの /workspace 内に移動してください。(ホスト環境の「{docker-compose.ymlを作成したフォルダ}/python310/workspace」フォルダ内に移動すれば良いです)
ここまで実施できたら、ローカル環境 python-labコンテナ内の作業に戻ります。
ノートブックの作成、定数の宣言
ブラウザで「http://127.0.0.1:7777/」にアクセスし、Jupyter notebook環境を開きます。docker-compose.ymlでポート番号を書き換えた場合は、書き換え後の番号を指定するようにしてください。
Launcherタブの「Notebook」-「Python 3」をクリックすると、新規ノートブックが作成されます。

最初のセルに下記のコードを貼り付けて実行しましょう。
# ベクトル変換前のデータのパス REFERENCE_JSON = './reference.json' # 基準データ TEST_JSON = './test.json' # 評価用データ # ベクトル変換後のデータのパス REFERENCE_EMBEDDED_NPY = './reference-embeddings.npy' # 基準データ TEST_EMBEDDED_NPY = './test-embeddings.npy' # 評価用データ
コーパスの取り込み
※ Google Colaboratoryでベクトル変換まで実行した場合は、この手順をスキップしてください。
python-labコンテナのターミナル(/workspace 内)で下記コマンドを実行し、Livedoorニュースコーパスをダウンロード・展開します。
wget https://www.rondhuit.com/download/ldcc-20140209.tar.gz tar -zxvf ldcc-20140209.tar.gz;
ニュース記事はカテゴリごとにフォルダ分けされています。今回はフォルダ名をそのままカテゴリ名として用います。
import os
CORPUS_DIR = './text' # Livedoorニュースコーパスの展開先
# フォルダ名=カテゴリ名
categories = [
f for f in os.listdir(CORPUS_DIR) if os.path.isdir(os.path.join(CORPUS_DIR, f))
]
categories
ニュース記事のファイルを読み込み、jsonファイルとして出力します。基準データと評価用データを7:3で分割して、それぞれ別のファイルとして出力しています。jsonファイルが既に存在する場合にはスキップします。
import numpy as np
from pathlib import Path
import os
import json
def get_article_text(path):
with open(path, 'r') as f:
lines = f.readlines()
lines = list(map(lambda x: x.rstrip(), lines))
return ' '.join(lines[2:])
def append_json(output_json_path, article_paths, category):
with open(output_json_path, 'a') as fp:
for article_path in article_paths:
json.dump({
"category": category,
"text": get_article_text(article_path)
}, fp)
fp.write('\n')
def load_corpus():
# 基準データ、評価用データのjsonが両方とも既に存在する場合は実行しない
if os.path.isfile(REFERENCE_JSON) and os.path.isfile(TEST_JSON):
return
# 続行する場合は、既存のjsonを削除する(後続処理で追記モードで書き込むため)
if os.path.isfile(REFERENCE_JSON):
os.remove(REFERENCE_JSON)
if os.path.isfile(TEST_JSON):
os.remove(TEST_JSON)
# 基準データ
reference_sentences = []
reference_categories = []
# 評価用データ
test_sentences = []
test_categories = []
for category in categories:
# 各カテゴリの記事ファイルのパスを取得
articles = np.array(list(Path(CORPUS_DIR).rglob(f'{category}/{category}-*.txt')))
# 基準データと評価用データを 7:3 に分割
reference, test = np.split(articles, [int(articles.size * 0.7)])
# JSONファイルとして保存
append_json(REFERENCE_JSON, reference, category)
append_json(TEST_JSON, test, category)
load_corpus()
pandasでjsonファイルを読み込んでおきます。
import pandas as pd reference_df = pd.read_json(REFERENCE_JSON, lines=True) test_df = pd.read_json(TEST_JSON, lines=True)
モデルの読み込み、ベクトル変換
※ Google Colaboratoryでベクトル変換まで実行した場合は、この手順をスキップしてください。
sentence-transformersのモデルを読み込みます。その後、コーパスのデータをベクトルに変換し、結果を npyファイルとして保存します。npyファイルが既に存在する場合はこの処理をスキップします。
from sentence_transformers import util, SentenceTransformer
def embedding():
# 既にファイルが存在する場合は実行しない
if os.path.isfile(REFERENCE_EMBEDDED_NPY) and os.path.isfile(TEST_EMBEDDED_NPY):
return
# モデルの読み込み
model = SentenceTransformer('stsb-xlm-r-multilingual')
# ベクトル変換、npy保存
reference_embeddings = model.encode(reference_df.text.values.tolist())
np.save(REFERENCE_EMBEDDED_NPY, reference_embeddings, allow_pickle=False)
test_embeddings = model.encode(test_df.text.values.tolist())
np.save(TEST_EMBEDDED_NPY, test_embeddings, allow_pickle=False)
embedding()
ベクトルデータベースの準備
PostgreSQLにベクトルデータベースの機能を追加できる拡張機能「pgvector」を使用します。環境構築でpgvectorのDockerイメージを使ってコンテナを作成していますので、ここではDBへの接続とテーブル作成を実行します。
DBへの接続に失敗するようでしたら、databaseコンテナが起動しているか確認してください。
テーブルにはidの他、カテゴリ名、文章、ベクトルのカラムを定義しています。sentence-transformersで変換したベクトルは768次元であるため、embeddingの型として「vector(768)」を指定しています。
from pgvector.psycopg import register_vector
import psycopg
import os
db = os.getenv("POSTGRES_DB")
username = os.getenv("POSTGRES_USER")
password = os.getenv("POSTGRES_PASSWORD")
host = os.getenv("POSTGRES_HOST")
port = os.getenv("POSTGRES_PORT")
DATABASE_URL = f"postgresql://{username}:{password}@{host}:{port}/{db}"
conn = psycopg.connect(DATABASE_URL, autocommit=True)
conn.execute('CREATE EXTENSION IF NOT EXISTS vector')
register_vector(conn)
conn.execute('DROP TABLE IF EXISTS documents')
conn.execute('CREATE TABLE documents (id bigserial PRIMARY KEY, category text, content text, embedding vector(768))')
ベクトルデータベースへの登録
先ほど定義したテーブルに合わせて基準データを追加します。
import pandas as pd
reference_df = pd.read_json(REFERENCE_JSON, lines=True)
test_df = pd.read_json(TEST_JSON, lines=True)
import numpy as np
reference_embeddings = np.load(REFERENCE_EMBEDDED_NPY)
test_embeddings = np.load(TEST_EMBEDDED_NPY)
insert_data = zip(reference_df.category.tolist(),
reference_df.text.tolist(),
reference_embeddings)
for category, content, embedding in insert_data:
conn.execute('INSERT INTO documents (category, content, embedding) VALUES (%s, %s, %s)', (category, content, embedding))
カテゴリ判定の精度測定
PostgreSQLの拡張機能pgvectorを使うとリレーショナルデータベースにベクトルを登録できるため、SQLによる検索ができます。例えば「id:1 のデータと類似度が高いデータの カテゴリ名とコサイン類似度を出力」するコードは以下のようになります。ベクトルの検索例はpgvectorのREADMEで紹介されていますのでご一読されることをお勧めします。
document_id = 1
query = '''
SELECT
category,
1 - (embedding <=> (SELECT embedding FROM documents WHERE id = %(id)s)) AS cosine_similarity
FROM documents
WHERE id != %(id)s
ORDER BY embedding <=> (SELECT embedding FROM documents WHERE id = %(id)s)
LIMIT 10
'''
neighbors = conn.execute(
query,
{'id': document_id}
).fetchall()
neighbors
出力結果:

今回のカテゴリ判定は、k近傍法っぽく以下のようなロジックにしてみます。(今回はこう決めるという話で、特にこのロジックが最適というわけではありません)
- コサイン類似度が高いデータ10件を取得する。
- カテゴリ数の多数決を行い、個数が最も多いカテゴリに分類する。
- カテゴリの個数が同じ場合は、コサイン類似度の合計値が最大のカテゴリに分類する。
id:1のデータを対象にこのロジックを試してみます。
document_id = 1
query = '''
WITH T AS (
SELECT
category,
1 - (embedding <=> (SELECT embedding FROM documents WHERE id = %(id)s)) AS cosine_similarity
FROM documents
WHERE id != %(id)s
ORDER BY embedding <=> (SELECT embedding FROM documents WHERE id = %(id)s)
LIMIT 10
)
SELECT
category,
COUNT(*) as count,
SUM(cosine_similarity) as sum_cosine
FROM T
GROUP BY category
ORDER BY count DESC, sum_cosine DESC
'''
neighbors = conn.execute(
query,
{'id': document_id}
).fetchall()
neighbors
出力結果:

この場合、「dokujo-tsushin」と「it-life-hack」が4つずつで並びましたが、「dokujo-tsushin」の方がコサイン類似度の合計値が大きいため、判定結果は「dokujo-tsushin」となります。neighbors[0][0]にアクセスすることでカテゴリ名を得ることができます。
neighbors[0][0]
出力結果:

それでは、このロジックで評価用データ全てを判定してみましょう。
categories = reference_df.category.unique().tolist()
# 基準データとの類似度をもとにカテゴリを判定する
def get_pred_category(embedding):
query = '''
WITH T AS (
SELECT
category,
1 - (embedding <=> %(embedding)s) AS cosine_similarity
FROM documents
ORDER BY embedding <=> %(embedding)s
LIMIT 10
)
SELECT
category,
COUNT(*) as count,
SUM(cosine_similarity) as sum_cosine
FROM T
GROUP BY category
ORDER BY count DESC, sum_cosine DESC
'''
result = conn.execute(
query,
{'embedding': embedding}
).fetchall()
return result[0][0]
# カテゴリごとの判定結果(正解/不正解の件数)を入れる変数
result_dict = dict()
for category in categories:
item = dict()
item["OK"] = 0
item["NG"] = 0
result_dict[category] = item
# 全ての評価用データのカテゴリを判定する
test_data = zip(test_df.category.tolist(), test_embeddings)
for true_category, embedding in test_data:
if true_category == get_pred_category(embedding):
result_dict[true_category]["OK"] += 1
else:
result_dict[true_category]["NG"] += 1
# 結果を出力
result_df = pd.DataFrame.from_dict(result_dict).T
result_df['正答率'] = result_df['OK'] / (result_df['OK'] + result_df['NG'])
result_df
出力結果:
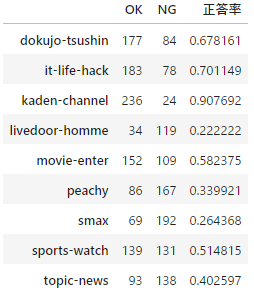
あらら…。正答率が50%にも満たないカテゴリがたくさんあります💦
Livedoor ニュースコーパスの全データのベクトルを2次元に圧縮し可視化し、原因を考察してみます。
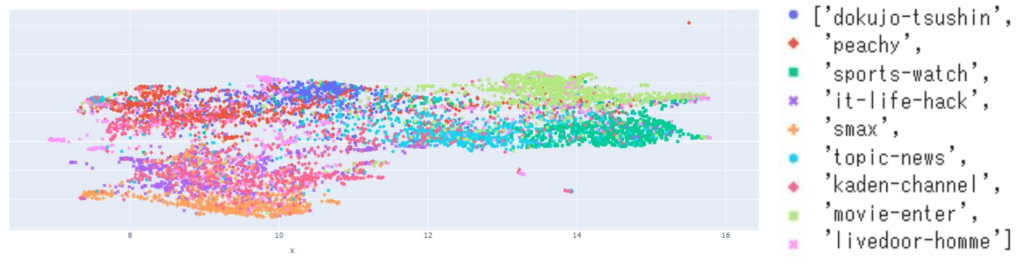
カテゴリごとにきれいにクラスター(データの群れ)を形成しているわけではなく、異なるカテゴリのベクトル同士が重なって配置されているように見えます。今回はsentence-transformersの学習済みモデルをそのまま使いましたが、Fine-TuningをしてLivedoor ニュースコーパスに特化させるように調整すれば、各カテゴリのデータがきれいに分かれるようなベクトル表現を得ることも可能だと思われます。
下記の記事内で紹介されているFine-Tuningの手法がそのまま適用できそうなので、機会があれば試してみたいと思います。
AI で文章をかしこく比較! Sentence-Transformers のご紹介 (SBテクノロジー株式会社さま)
2クラス分類の実装例
ここまでは「9種類あるカテゴリのどれに該当するかを判定する」仕組みを実装してきましたが、「あるカテゴリに該当するか否か(Yes or Noの2クラス)判定」も試してみます。
ここでは、コサイン類似度の閾値を定義し「dokujo-tsushin」カテゴリに該当するか否かを以下のようなロジックで判定してみます。(「10個」や「0.60」は適当に設定しています)
- 「dokujo-tsushinカテゴリの基準データのうち、入力データに近い10個を取り出す。
- 取り出した10個のコサイン類似度の平均を算出する。
- コサイン類似度の平均が閾値(0.60)以上であれば「dokujo-tsushinに該当する」、それ以外なら「該当しない」と判定する。
実装例は次のようになります。
CHECK_TARGET_CATEGORY = 'dokujo-tsushin'
COSINE_THRESHOLD = 0.60
def get_neighbors_cosine_similarity(category, embedding):
query = '''
WITH T AS (
SELECT
category,
1 - (embedding <=> %(embedding)s) AS cosine_similarity,
RANK() OVER(ORDER BY (1 - (embedding <=> %(embedding)s)) DESC) AS rank
FROM documents
WHERE category = %(category)s
ORDER BY embedding <=> %(embedding)s
LIMIT 10
)
SELECT
AVG(cosine_similarity)
FROM T
'''
result = conn.execute(
query,
{
'embedding': embedding,
'category': category
}
).fetchall()
return result[0][0]
indices = test_df.query(f'category == "{CHECK_TARGET_CATEGORY}"').index
if get_neighbors_cosine_similarity(CHECK_TARGET_CATEGORY, test_embeddings[indices[0]]) >= COSINE_THRESHOLD:
print(f'カテゴリ{CHECK_TARGET_CATEGORY} に該当します')
else:
print(f'カテゴリ{CHECK_TARGET_CATEGORY} に該当しません')
このように判定ロジックの実装次第では2クラス分類も解くことができる可能性があります。
まとめ
今回のブログでは、sentence-transformersの学習済みモデルを使って文章の類似度からカテゴリを判定する仕組みを考えてみました。データセットとしてLivedoorニュースコーパスを用いた場合は高い精度を出すことは叶いませんでした。しかし今回は「前処理、Fine-Tuning、他モデルへの変更、判定ロジックの追究」などの試行錯誤はまったくしていませんので伸びしろはまだたくさんあります。
類似文章判定の可能性を感じていただけましたら、お手元のデータセットでぜひ試してみてください。
参考文献

