当社ではシステムレポートを作成するため、SQLでデータを抽出して加工することがあります。
レポート作成を繰り返す中、お決まりの考え方やSQLスニペットが溜まってきました。
特に縦方向の集計はヒトクセあり、最初は書き方に戸惑うことも多いと思います。
ですが蓋を開けてみれば意外と単純な話だったりするので、ここいらで解説をしておきたいと思い記事を書いています。
それではいってみましょう。
目次
この記事の対象者
- SQLでgroup by を使ったことがある方
- 行内で四則演算ができる方
- 分析関数・Window関数ってなんだよ?という方
この記事で使うテストデータ
まず本記事で扱うサンプルデータを紹介します。
ユースケースとして毎日何らかのサービスを選び、課金するシステムを想定してください。
ログインをしなくてもサービス料金が発生し続けます。無料のサービスを選ぶと課金が終わります。
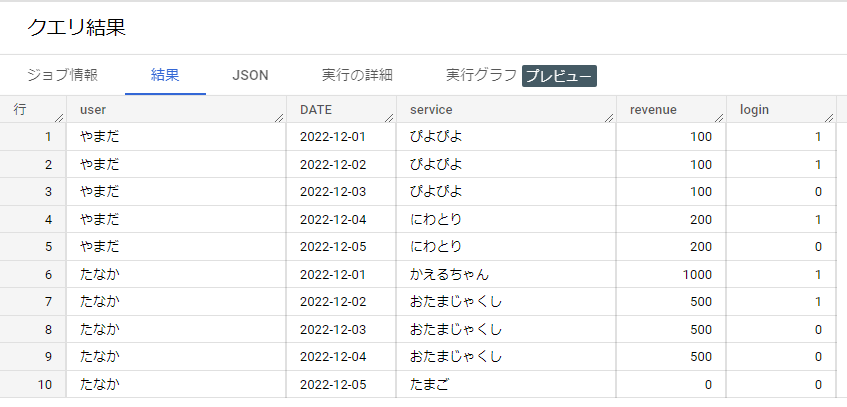
そのような状態を以下のデータとして表現しました。
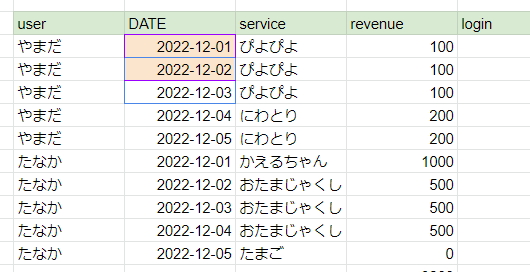
“やまだ”さんと”たなか”さんの5日間の課金状態を表しています。
緑のハイライトは物理名と論理名です。
| ユーザー | 日付 | 使ったサービス | 売上 | ログイン |
| user | date | service | revenue | login |
| やまだ | 2022-12-01 | ぴよぴよ | 100 | 1 |
| 2022-12-02 | ぴよぴよ | 100 | 1 | |
| 2022-12-03 | ぴよぴよ | 100 | 0 | |
| 2022-12-04 | にわとり | 200 | 1 | |
| 2022-12-05 | にわとり | 200 | 0 | |
| たなか | 2022-12-01 | かえるちゃん | 1,000 | 1 |
| 2022-12-02 | おたまじゃくし | 500 | 1 | |
| 2022-12-03 | おたまじゃくし | 500 | 0 | |
| 2022-12-04 | おたまじゃくし | 500 | 0 | |
| 2022-12-05 | たまご | 0 | 0 |
このデータをBigQueryの一時テーブルに定義して使っていきます。
WITH sample_data AS (
SELECT 'やまだ' AS user, CAST('2022-12-01' AS DATE) AS DATE, 'ぴよぴよ' AS service, 100 AS revenue, 1 AS login UNION ALL
SELECT 'やまだ' AS user, CAST('2022-12-02' AS DATE) AS DATE, 'ぴよぴよ' AS service, 100 AS revenue, 1 AS login UNION ALL
SELECT 'やまだ' AS user, CAST('2022-12-03' AS DATE) AS DATE, 'ぴよぴよ' AS service, 100 AS revenue, 0 AS login UNION ALL
SELECT 'やまだ' AS user, CAST('2022-12-04' AS DATE) AS DATE, 'にわとり' AS service, 200 AS revenue, 1 AS login UNION ALL
SELECT 'やまだ' AS user, CAST('2022-12-05' AS DATE) AS DATE, 'にわとり' AS service, 200 AS revenue, 0 AS login UNION ALL
SELECT 'たなか' AS user, CAST('2022-12-01' AS DATE) AS DATE, 'かえるちゃん' AS service, 1000 AS revenue, 1 AS login UNION ALL
SELECT 'たなか' AS user, CAST('2022-12-02' AS DATE) AS DATE, 'おたまじゃくし' AS service, 500 AS revenue, 1 AS login UNION ALL
SELECT 'たなか' AS user, CAST('2022-12-03' AS DATE) AS DATE, 'おたまじゃくし' AS service, 500 AS revenue, 0 AS login UNION ALL
SELECT 'たなか' AS user, CAST('2022-12-04' AS DATE) AS DATE, 'おたまじゃくし' AS service, 500 AS revenue, 0 AS login UNION ALL
SELECT 'たなか' AS user, CAST('2022-12-05' AS DATE) AS DATE, 'たまご' AS service, 0 AS revenue, 0 AS login
)
SELECT * FROM sample_data
準備ができました。この一時テーブルに対してSQLを記述していきます。
集計関数についておさらい
まずは集計関数Group Byのおさらいをしましょう。
Group by
SQLで集計をするときに使うのがGroup By句です。Excelの集計関数SUMなどに該当します。
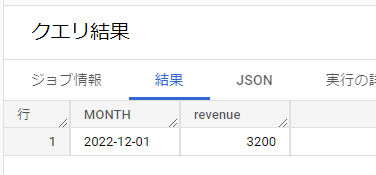
例えば、12月の売上合計を出す時などです。
SELECT DATE_TRUNC(DATE, MONTH) AS MONTH
, SUM(revenue) AS revenue
FROM sample_data
GROUP BY DATE_TRUNC(DATE, MONTH)
DATE_TRUNC関数でDATEを月単位に丸め、12月の合計売上を求めています。
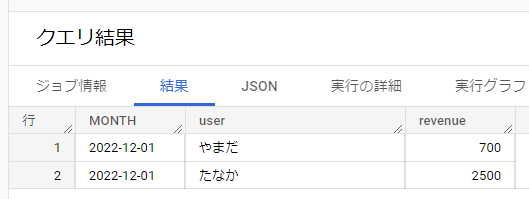
ユーザー毎の売上を出すには、GROUP BYにユーザーを足せば事足ります。
SELECT DATE_TRUNC(DATE, MONTH) AS MONTH
, user AS user
, SUM(revenue) AS revenue
FROM sample_data
GROUP BY DATE_TRUNC(DATE, MONTH), user
簡単なおさらいでした。
ところで、同列に合計金額を出したい場合はどうでしょうか?
Google Sheetsで表現すると次のような表を作りたい場合です。
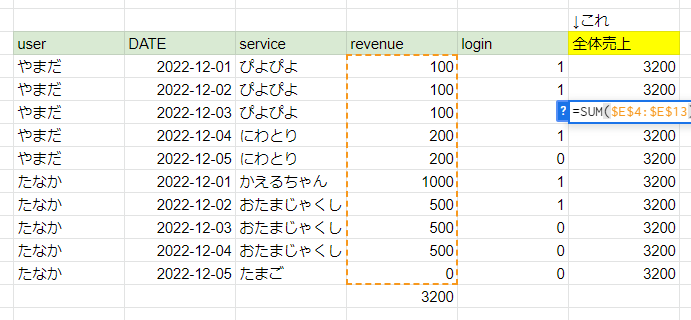
自身の行をカレントとして、上下すべてのタテ集計を行う必要があります。
Window関数はそんな夢を叶えてくれる便利な関数です。
Window関数(分析関数)
Window関数(分析関数)とは
ウィンドウ関数の呼び出しによると
ウィンドウ関数は分析関数とも呼ばれ、行のグループに対して値を計算して、各行に対して 1 つの結果を返します。これは、行のグループに対して 1 つの結果を返す集計関数とは異なります。
https://cloud.google.com/bigquery/docs/reference/standard-sql/window-function-calls?hl=ja
とのことで、行全体を縦に集計するSUMとは異なる。ということを書いています。
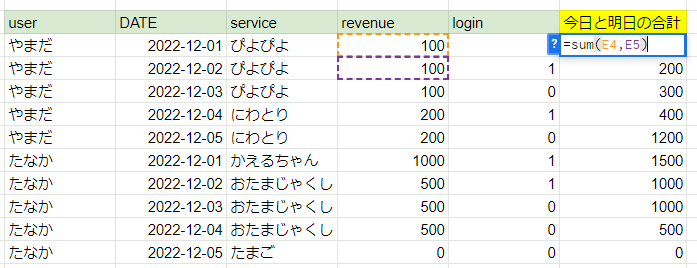
“行のグループ”とは、「今日と明日の売上合計」を表現する場合、自身の行とその下の行の2行の事を指します。
下の行(2行目)を主役にすると、更に自身と自身の下の2行が1つのグループとなります。
「12/01と12/02」「12/02と12/03」…が、それぞれ行グループの連なりになります。
“各行に対して1つの結果を返す”とは、それぞれの行グループを計算した結果を、主役となる行に返すということです。
次のGoogle Sheetsの式が参考になるかと思います。
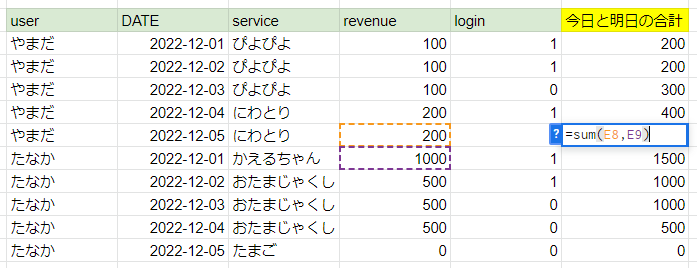
集計関数すべての行データがSUMやADVの対象として計算されました。
Window関数は行データの集計範囲を制御することができるということです。
Window関数の構文
考え方がわかれば、次は構文です。
本家マニュアルを見ると膨大なパラメータが目に入ってきて驚きます。
function_name ( [ argument_list ] ) OVER over_clause over_clause: { named_window | ( [ window_specification ] ) } window_specification: [ named_window ] [ PARTITION BY partition_expression [, ...] ] [ ORDER BY expression [ { ASC | DESC } ] [, ...] ] [ window_frame_clause ] window_frame_clause: { rows_range } { frame_start | frame_between } rows_range: { ROWS | RANGE }https://cloud.google.com/bigquery/docs/reference/standard-sql/window-function-calls?hl=ja#syntax
色々あります。ここでは主要な構文に焦点を当てていきます。
手始めに先程説明に挙がった「今日と明日の売上合計」を作っていきましょう。
今日と明日の売上合計
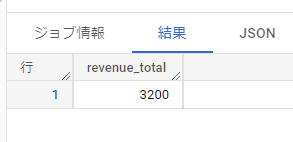
まず最初にただのSUMを書きます。
SELECT sum(revenue) as revenue_total
FROM sample_data
Group By句が無いのでちょっと気持ち悪いですが、値が帰ってきます。
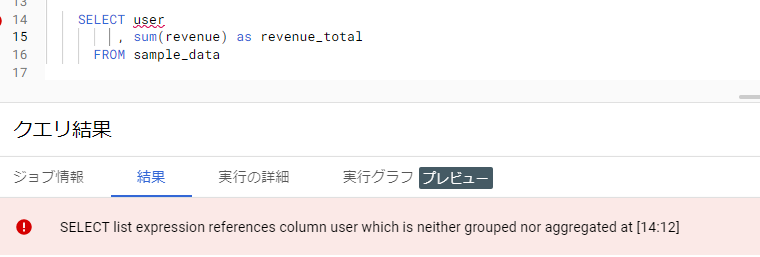
これは集計関数として動作しているため、例えばuser を列に記述すると構文エラーになります。
Group By句にuser がないか、集計関数が使われていないというエラーです。
ここで使っているSUMは先程引用したマニュアルのfunction_name になりますので、そのままマニュアル通りOVER xxxx部分を書いていきます。
いくつかあるパラメータのうち、OVER ~~ ORDER BYを追加しました。SELECT結果と並び順を一緒にしているので、結果としては上から順に累計処理が行われます。DESCキーワードを付けると下からの累計になります。
SELECT *
, SUM(revenue) OVER (ORDER BY user desc, date) AS revenue_total
FROM sample_data
ORDER BY user desc , date
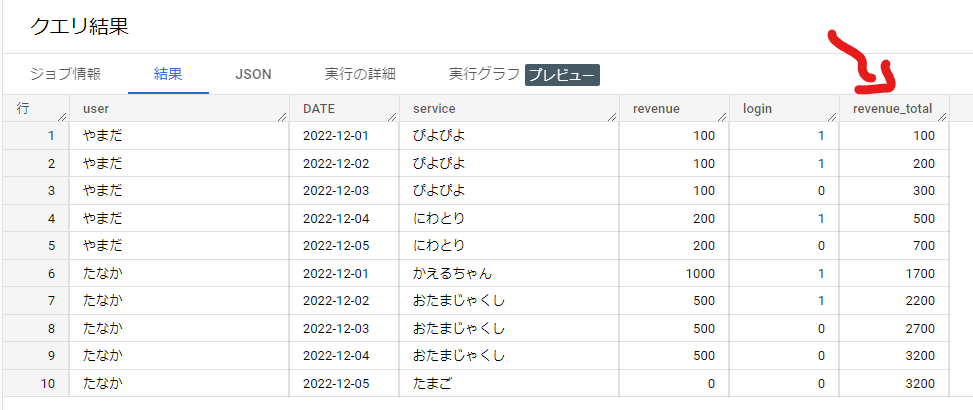
OVER (ORDER BY user desc, date)の部分でuser、DATE順に累計しなさいよ。という命令を行っています。
SELECT句に対する並び順とWindow関数に指定する並び順はそれぞれ別モノとして動作することにご注意ください。
またOVERキーワードを使ってSUMを記述したのでWindow関数として認識され、Group Byを書かなくても他の列を表示させることができています。
結果は毎行 revenueが足し込まれる結果となりました。
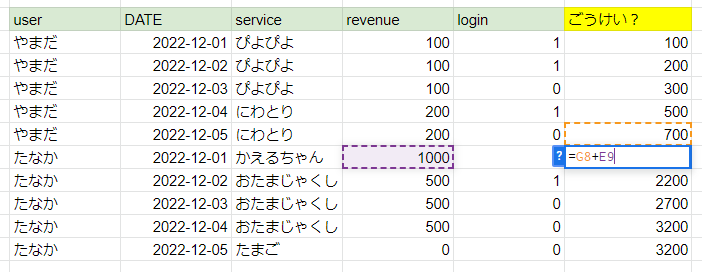
Google Sheetsだと自身+これまでのrevenue合計の式が成り立ちます。
目的は「今日と明日の売上合計」なので、集計範囲を絞っていきます。
SELECT *
, SUM(revenue) OVER (ORDER BY user desc, date ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS revenue_total
FROM sample_data
ORDER BY user desc , date
行範囲を絞るにはROWS BETWEEN ●● AND ●●構文を指定します。
今回は現在行CURRENT ROWから、次の行1 FOLLOWINGを指定しています。
これがWindow関数における行グループを決めるフレームと呼ばれるもので、詳しい記述方法はコチラに書いています。
結果はコチラ
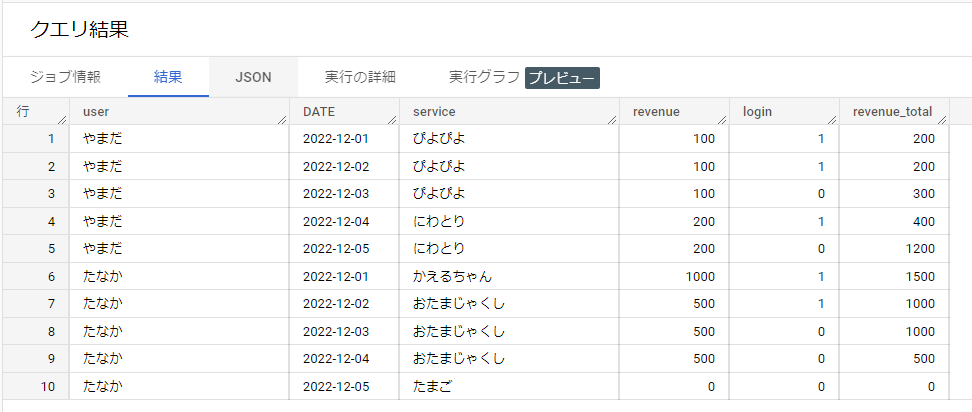
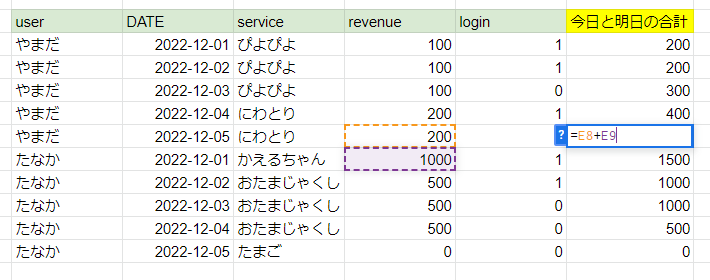
お目当ての売上金額を求める事ができました。
Google Sheetsで作った式とも一致しました。
想像以上に簡単だと思いませんか?
ユーザー毎に売上金額を出してみる
他の構文も見るついでに行番号を足しつつ、ユーザー毎の合計売上と、合計売上に対する当日の売上比率を出してみます。
SELECT ROW_NUMBER() OVER (ORDER BY user desc, date) AS ROW_NO
, *
, SUM(revenue) OVER (PARTITION BY user ORDER BY user desc) AS user_total
, revenue / SUM(revenue) OVER (PARTITION BY user ORDER BY user desc) AS ratio
FROM sample_data
ORDER BY user desc , date
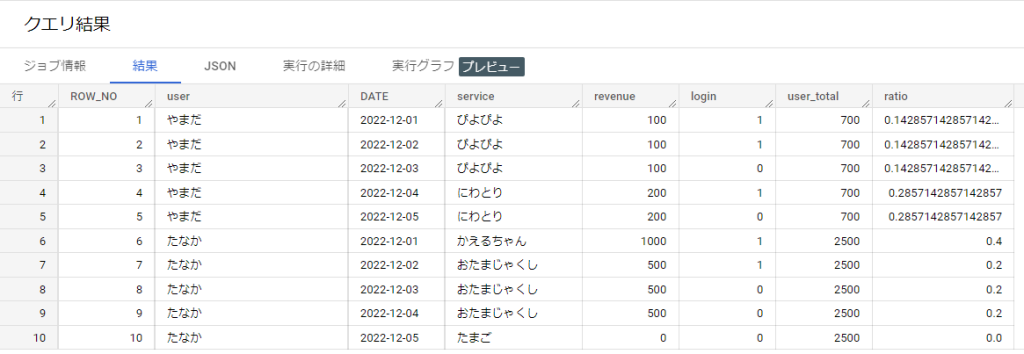
PARTITION BYというキーワードを使いました。これは動きの通り SUMをユーザー毎に行う指定となります。
Window関数の結果は集計関数と異なり、行内の他の列と四則演算が可能なのでrevenue / SUM(revenue) …このような記述ができます。計算によりユーザー毎の全体売上に占める当日売上の割合も出すことができました。
ログインの履歴
他にも便利なWindow関数がいくつもあり。簡単なキーワードで複雑な処理を実現できるので楽ちんです。
SELECT *
, LAST_VALUE(login) OVER (PARTITION BY user ORDER BY user desc) AS last_value_login
, FIRST_VALUE(login) OVER (PARTITION BY user ORDER BY user desc) AS first_value_login
FROM sample_data
ORDER BY user desc , date
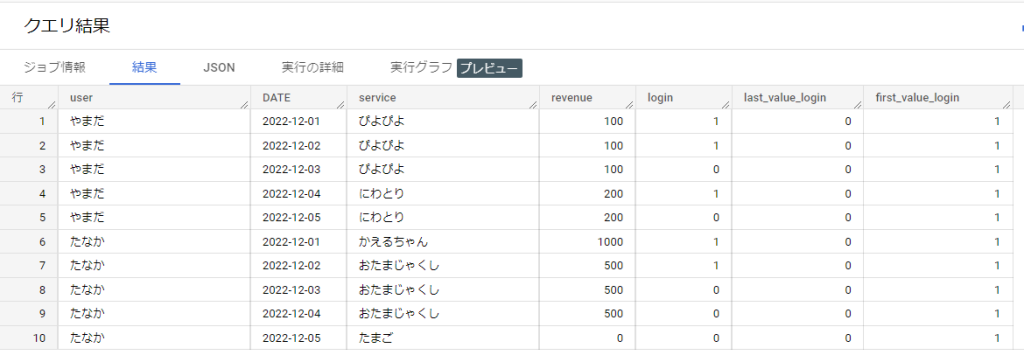
例えばこんな形で、フレーム内の最初の値、最後の値を取得することができます。
キーブレイク
上の行と現在行を見比べ、異なるサービスを使った日にフラグをつけたりもできます。
SELECT *
, FIRST_VALUE(service) OVER (PARTITION BY user ORDER BY user desc ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS prev_service
, CASE WHEN service = FIRST_VALUE(service) OVER (PARTITION BY user ORDER BY user desc ROWS BETWEEN 1 PRECEDING AND CURRENT ROW)
THEN 0
ELSE 1
END AS new_service
FROM sample_data
ORDER BY user desc , date
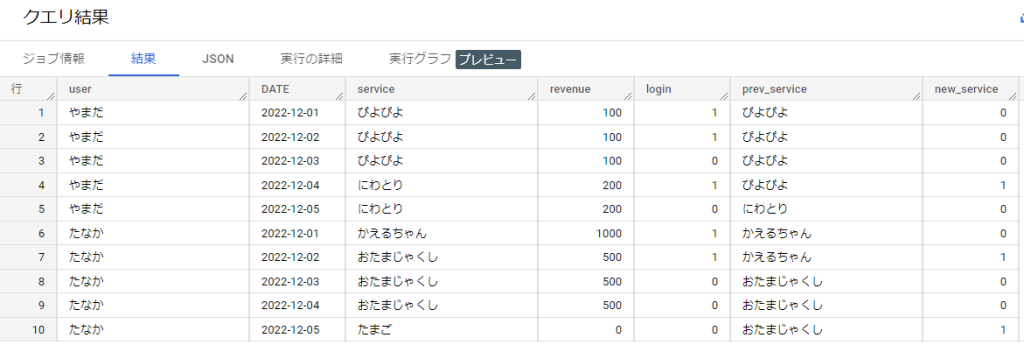
フレームをひとつ上の行までにしてFIRST_VALUEで値を取得し、現在行のserviceと比較してCASE文でフラグを立てています。利用サービスが変わった時のアラートに活用できそうです。
データポータルでもWindow関数
BigQueryで抽出したデータは、データポータルに取り込んでレポートにするような使い方をします。
データポータルへの取り込み方法は割愛しますが、以下がサンプルデータを取り込んだところです。
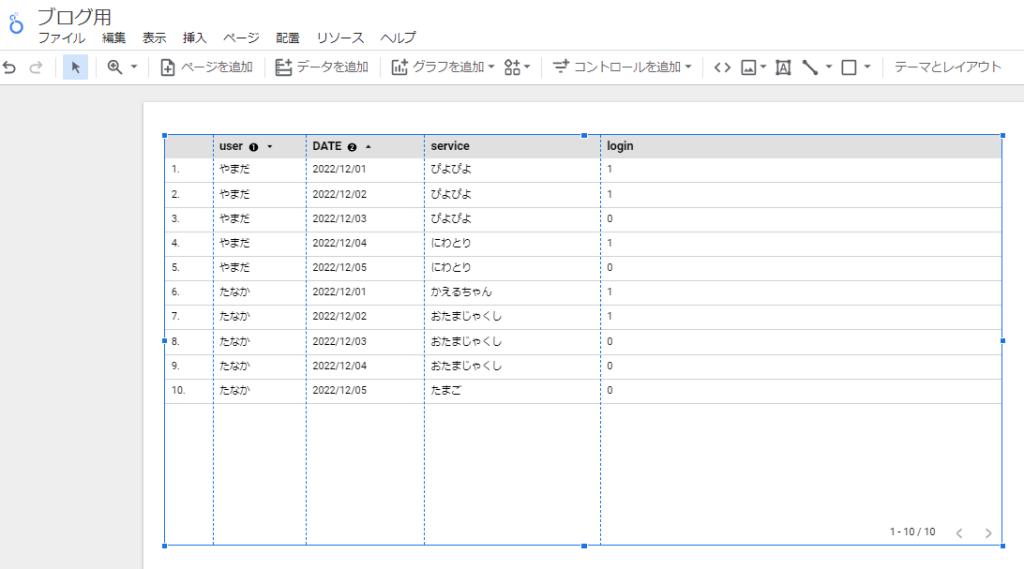
実はWindow関数を使わなくてもシンプルな累計計算であればGUIだけで利用できてしまうのです。
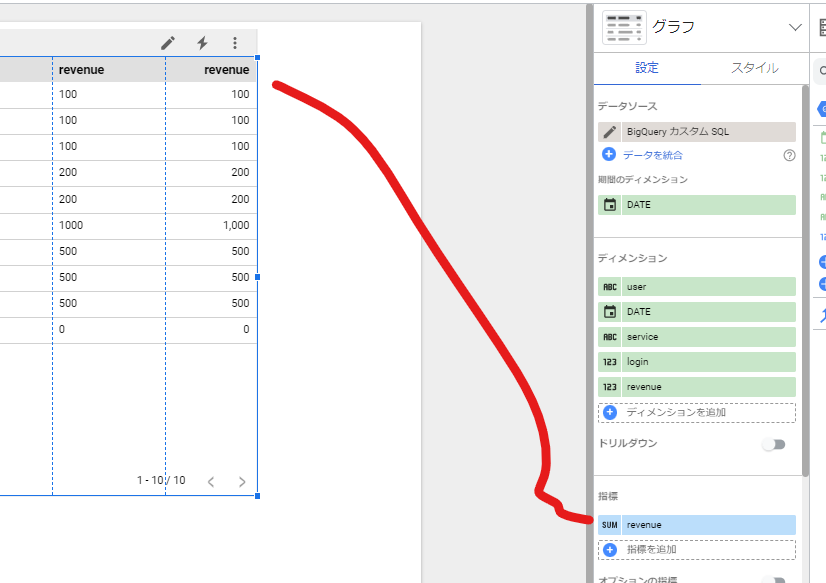
それが「実行中の~~」という指標を使う方法です。
まず指標にrevenueを置いて・・・
関数に「実行中の合計」を指定
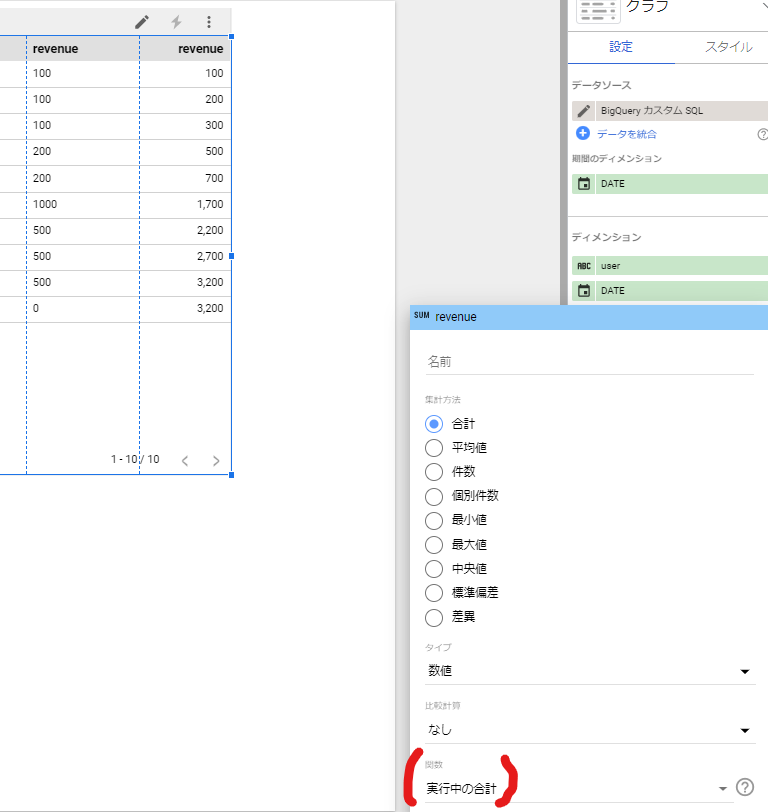
こうすることで、Window関数のSUMのような事ができます。
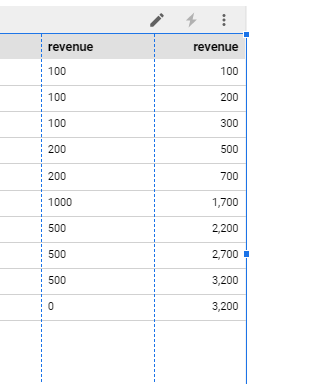
「実行中の~」という日本語が分かりにくいですが、いわば現在行のことなのでしょう。
さいごに
BigQueryを使ってWindow関数の考え方を解説し、データポータルで簡易的な累計処理も学びました。
いかがでしたでしょうか?
最初はマニュアルに圧倒されますが、考え方と書き方を紐解けば気軽に扱えるものだという事がお分かりいただけたかと思います。
これを機に是非活用いただけますと幸いです。
それでは、よきデータ分析ライフを!


