こんにちは。
今回は Relay を用いた GraphQL のスキーマ設計の話をしたいと思います。
目次
はじめに
Relay とは Meta 社が開発している GraphQl クライアントです。
複雑なコンポーネントに対してデータフェッチの容易性を確保し、あらゆるスケールでハイパフォーマンスを発揮することを目的としています。
現在もっとも広く使用されている GraphQL クライアントはおそらく Apollo Client になるかと思います。
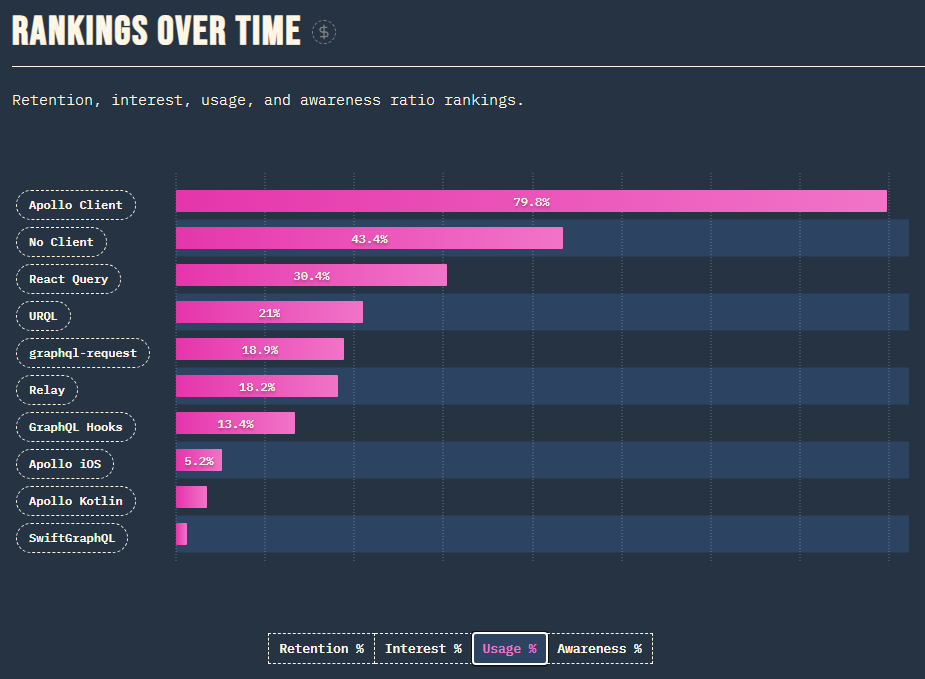
Apollo Client は機能も豊富で、さまさまな要求に応じることができることが特徴であるかと思いますが、一方でその自由さゆえに、開発者がしっかりとした設計指針を持っていないと実装が混乱する可能性があります。(まあそれ自体は Apollo Client の欠点とは言えないと思いますが)
Relay は上記のグラフを見る限りではまだそれほど広く使用されていないように見えますが、「こう書くべき」という明確な設計指針があるため、開発者がベストプラクティスに沿って実装することが容易です。
今回は Relay の設計指針を通して、GraphQL スキーマ設計のベストプラクティスを学んでいきたいと思います。
Relay の特徴
Relay の主な特徴としては、以下のようなものがあります。
コンポーネント単位での宣言的データフェッチ
各コンポーネント単位で必要なデータを宣言的に定義することができます。
これの何がうれしいかというと、各コンポーネントは結局自分にとって必要なデータの事だけを考えておけばいいので、面倒な親から子への値の受け渡しとかを考える必要がなくなります。また、ほとんどの実装例でコンポーネントのファイル内に GraphQL クエリが一緒に書かれていることからこのような書き方が一般的なのだろうと推察しますが、こうすることでコンポーネントをまたいだクエリの使いまわしを防ぐことができます。
クエリの使いまわしはたびたび行われていますが、ちょっとした変更で容易にオーバーフェッチを生む点や、一度追加したフィールドを削除することが困難(そのフィールドが使用されている可能性を排除するためにはそのクエリを使用しているコンポーネントの実装まで確かめる必要がある)なため、明らかに避けるべきパターンです。
また、GraphQL クエリを定義したファイル内で直接フィールドが使用されていない場合は、以下のように Warning が表示されます。直接そのフィールドを使用しないのなら、そのフィールドを直に使用するコンポーネントといっしょに Fragment として別ファイルに切り出すように注意されます。プロジェクト全体の設定としてこのルールを無視できないようにしておけば、ある程度の治安を維持することができそうです。
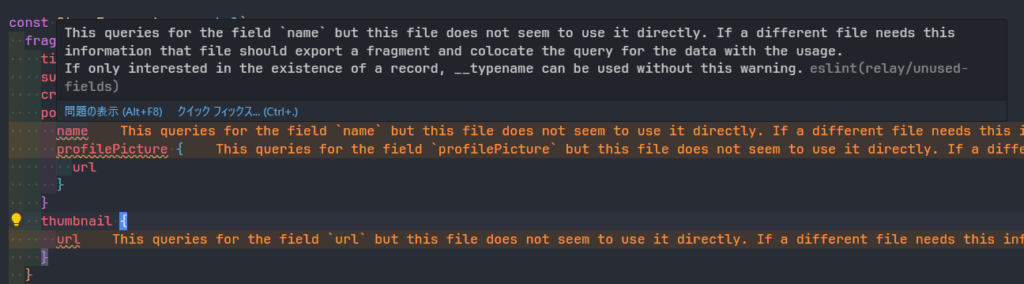
コード例
トップレベルのコンポーネントが以下のような状態です。
const NewsfeedQuery = graphql`
query NewsfeedQuery {
topStories {
id
...StoryFragment
}
}
`;
export default function Newsfeed({}) {
const data = useLazyLoadQuery<NewsfeedQueryType>(NewsfeedQuery, {});
const stories = data.topStories;
return (
<div className="newsfeed">
{stories.map((story) => (
<Story key={story.id} story={story} />
))}
</div>
);
}
NewsfeedQuery 内で直接指定しているフィールドは id だけです。同ファイル内で定義されているコンポーネントでは id だけを利用しているので、このようになってます。 同様に、Story.tsx 内で定義されている StoryFragment では、Story コンポーネント内で使用するフィールドだけを直接指定しています。それ以外(Story コンポーネント内で使用する子コンポーネント)で使用するデータは、そのための Fragment で定義されます。
type Props = {
story: StoryFragment$key;
};
const StoryFragment = graphql`
fragment StoryFragment on Story {
title
summary
createdAt
poster {
...PosterBylineFragment
}
thumbnail {
...ImageFragment @arguments(width: 400)
}
}
`;
export default function Story({ story }: Props) {
const data = useFragment(StoryFragment, story);
return (
<Card>
<PosterByline poster={data.poster} />
<Heading>{data.title}</Heading>
<Timestamp time={data.createdAt} />
<Image image={data.thumbnail} />
<StorySummary summary={data.summary} />
</Card>
);
}
コンポーネント内では useFragment hooks を使って自身が受け取るべきデータを特定します。useFragment の引数は、そのコンポーネントが受け取るべき fragment と、StoryFragment$key として定義されている fragmentRef 引数(実際のデータを特定するための参照)です。この key は Relay が自動生成するもので、実態はおおむね以下のようになっています(長いので一部省略しています)。
{
"id": "4",
"__fragments": {
"StoryFragment": {}
},
"__id": "4",
"__fragmentOwner": {
"identifier": "aebbd0c19babde43569dbd6ea07914e4{}",
"node": {
"fragment": {
"argumentDefinitions": [],
"kind": "Fragment",
"metadata": null,
"name": "NewsfeedQuery",
"selections": [...],
"type": "Query",
"abstractKey": null
},
"kind": "Request",
"operation": {
"argumentDefinitions": [],
"kind": "Operation",
"name": "NewsfeedQuery",
"selections":[...]
},
"params": {
"cacheID": "aebbd0c19babde43569dbd6ea07914e4",
"id": null,
"metadata": {},
"name": "NewsfeedQuery",
"operationKind": "query",
"text": "query NewsfeedQuery {\n topStories {\n id\n ...StoryFragment\n }\n}\n\nfragment ImageFragment_3XLoCc on Image {\n url(width: 60, height: 60)\n altText\n}\n\nfragment ImageFragment_OxVt3 on Image {\n url(width: 400)\n altText\n}\n\nfragment PosterBylineFragment on Actor {\n __isActor: __typename\n id\n name\n profilePicture {\n ...ImageFragment_3XLoCc\n }\n}\n\nfragment StoryFragment on Story {\n title\n summary\n createdAt\n poster {\n __typename\n ...PosterBylineFragment\n id\n }\n thumbnail {\n ...ImageFragment_OxVt3\n }\n}\n"
},
"hash": "06e6b6b9d307eae64894bc47ffa26664"
},
"variables": {},
"cacheConfig": {
"force": true
}
},
"__isWithinUnmatchedTypeRefinement": false
}
上記の ImageFragment では親画面から width を受け取っています。子コンポーネントの側では、下記のように@argumentDefinitions を用いて親画面から渡された引数を受け取ることができます。
const ImageFragment = graphql`
fragment ImageFragment on Image
@argumentDefinitions(
width: { type: "Int", defaultValue: null }
height: { type: "Int", defaultValue: null }
) {
url(width: $width, height: $height)
altText
}
`;
type Props = {
image: ImageFragment$key;
};
export default function Image({ image }: Props): React.ReactElement {
const data = useFragment(ImageFragment, image);
return (
<img
key={data.url}
src={data.url}
alt={data.altText}
width={60}
height={60}
/>
);
}
このように、各コンポーネントでは自分に必要なデータだけに関心を持ち、他のコンポーネントに必要なデータについてはそれぞれのコンポーネントが自分で管理するかたちになります。
props の形で親から子へバケツリレーするやり方と比べると、コンポーネント間の結合度を低く抑えることができていることが分かります。逆にコンポーネントとデータ取得用のクエリとの結合度は高くなっています。これにより、自然とコンポーネント間での GraphQL クエリの再利用ができなくなります。
クエリを再利用できる状態にしておくと、知らないうちにどこかの誰かがフィールドをどんどん追加していくものです。そうなると、クエリを利用しているコンポーネントでは余計なデータフェッチが発生することになります。また、不要になったフィールドを削除しようとした時にはそのクエリを利用しているコンポーネントの実装、動作をすべて確認してからでないと削除できません。結果として、変更に弱い構造になってしまいます。適切にクエリとコンポーネントを結びつけることでこのような問題を回避することができます。
Fragment Colocation
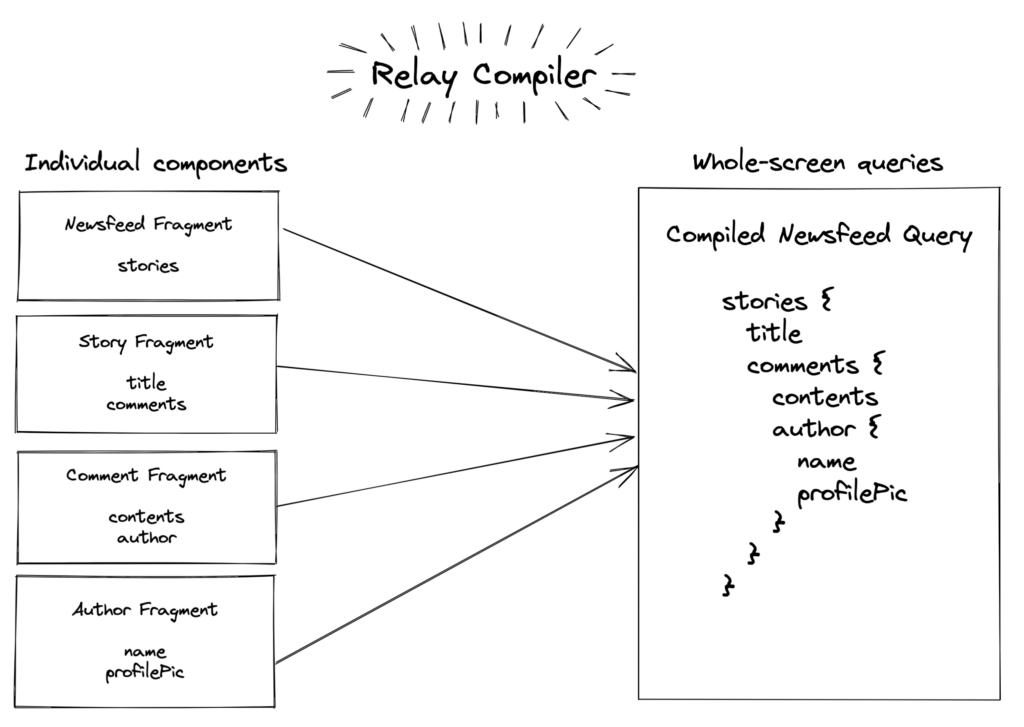
Relay はコンポーネントレベルで宣言されたクエリ、フラグメントを集めて再構成し、フィールドの重複を除去します。多数の子コンポーネントを組み合わせて画面を構成する場合、各子コンポーネントが Fragment 内で指定しているフィールドが重複する可能性があります。もしもそのままそれぞれの Fragment の定義をフェッチしてしまうと、重複したフィールドの分よけいにデータフェッチが発生してしまいます。
Relay では Relay Compiler が各コンポーネントが持つ Fragment をひとまとめにし、画面全体で必要なデータを1つのクエリとして再構成します。これにより、最終的なリクエストからは不要なフィールドが除去され、オーバーフェッチが発生しないようになります。リクエストを1つに纏めることで無用なラウンドトリップタイムを削減できます。
クライアントにもサーバにも、規約にのっとった実装を強制できる
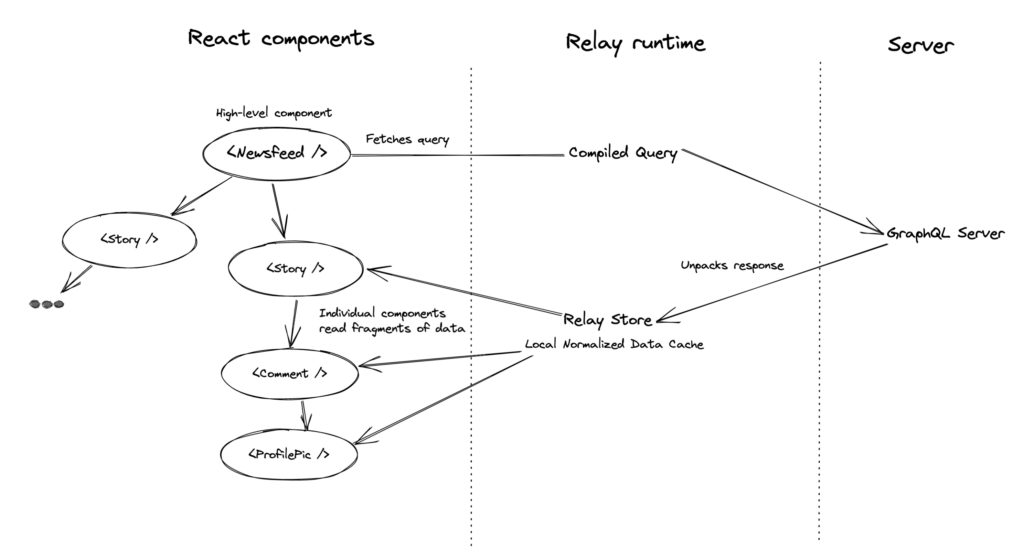
上記のような内容は実装としてはクライアント側の話になりますが、Relay はサーバ側の実装にも規約を強制することができます。例えば、Relay はクライアント側でのデータのキャッシュをサポートしていますが、そのためには各データに一意の ID が必要になります。Relay はサーバ側に対して、各データに一意の ID を付与するように要求します。なお、サーバが従うべき指針は GraphQL Server Specification に書かれています。
おまけ
少し前に GraphQL London 2023 でこんな発表がありました。
GraphQL London 2023/9/7
Tom Harding – GraphQL without Relay is not worth it
Relay を使わないなら GraphQL を使う価値はないよ、というようなタイトルで、すこし煽りも入った発表だったのですが、興味深い内容でした。内容を大まかに要約すると、以下のようになります。(以下筆者要約)
時代の変化に対応するには素早く開発する必要があるが、開発者を増やすことでは開発速度を上げることはできない。複数の開発者が同時並行的に機能開発を行うことができれば開発速度を上げることができるが、そうするにはどんな方法があるか? ここでは3つ挙げる。
- サービスを互いに独立したマイクロサービスの組み合わせとして設計する
- UIコンポーネントごとに責任者を明確にする
- Relay スタイルで GraphQL を使用する
1. サービスを互いに独立したマイクロサービスの組み合わせとして設計する
1番目の「サービスを互いに独立したマイクロサービスの組み合わせとして設計する」は、文字通りの意味で、サービス全体をマイクロサービスに切り分けて、それぞれで開発を進める手法。こうすればたしかに複数の開発者が同時並行に開発を行うことができるが、反面アプリケーション全体のレスポンスタイムが悪化するという問題がある(各サービス間での状態を共有するためのコストを無視できないため)。また、開発者がそれぞれのマイクロサービスにロックインされてしまい、別のマイクロサービスの開発に即座に移動するといったことが難しくなる可能性がある。
2. UIコンポーネントごとに責任者を明確にする
2番目の「UIコンポーネントごとに責任者を明確にする」については、例えば画面ごと、コンポーネントごとに担当者を決めてそれぞれがばらばらに開発する、というようなスタイルを指す。開発者ごとの責任範囲が明確になり、自分の担当範囲に限れば状態の管理も簡単になる。しかし、親から子への状態の受け渡しや、状態の共有については難しい問題が残る。親と子の担当者が別々の場合など、だれが何をすればいいのか明確ではない。
3. Relay スタイルで GraphQL を使用する
3番目の「Relay スタイルで GraphQL を使用する」について。Relay が推奨する方法を使えば、コンポーネントは独立しており、状態も一定のままを保つことができる。必要なデータは fragment をつかい各コンポーネントが管理する。高度な最適化はサーバにまかせる。(要約ここまで)
これだけを見ると、確かに良さそうに見えます。
ただ、Relay の issue を見てみると Next.js と合わせて使用するケースや graphql-codegen と一緒に使うケースなど、他のライブラリとの相性で問題が起こることも多いようです。Relay 自体の学習コストもそこそこ高いこともあり、気軽に導入できるものでもなさそうですが、Relay が示す方向性はかなり魅力的なもののように見えます。
最後に
以下は React の共同作成者で元 Meta の Dan Abramov 氏のつぶやきです。「Relay がやるような方法で複数のコンポーネントの fragment をまとめ上げることをしていないなら、GraphQL を使用する利点の 80 % を失っています。」
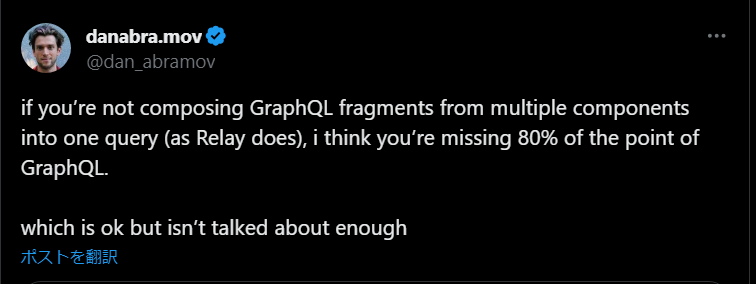
実際にプロジェクトに Relay を使用するとなると越えるべきハードルは高いとも思いますが、GraphQL を使用していて設計に悩んでいる際は参考になるのではないでしょうか。
参考文献など
- Relay 公式ページ
- GraphQL Server Specification
- GraphQL London 2023/9/7 Tom Harding – GraphQL without Relay is not worth it
- Scaling frontend app teams using Relay
- Re-introducing Relay | Robert Balicki React Conf 2021
- Getting Started with Relay Modern, React & GraphQL (Full Tutorial) by Prisma
- Why Relay is a Must for your GraphQL APIs – Marion Schleifer, Hasura GraphQL Conf 2023
- Relay: the GraphQL client that wants to do the dirty work for you
- Relay に学ぶ GraphQL のスキーマ設計
- Apollo Client にいろいろ足しながら Relay と比較する
- Relay: the GraphQL client that wants to do the dirty work for you
- The State of GraphQL 2022
- Fixing the Billion Dollar Mistake Client Controlled Nullability – Stephen Spalding, Netflix GraphQLConf 2023


